“Optimiser choice matters most early in training. LR-schedule choice matters most late. If you have to pick one to obsess over, pick the schedule.
”
A practical webinar on the part of deep-learning training that doesn't get talked about enough: the optimiser and the learning-rate schedule are often the difference between a model that converges and one that doesn't - regardless of how much capacity you've thrown at the architecture.
We built a live optimiser-trajectory plot for this session so you can watch SGDStochastic Gradient Descent - updates model parameters in the direction of the negative gradient computed on a mini-batch. The classical, noise-friendly optimiser; with momentum, still competitive on image classification at convergence., AdamAdaptive Moment Estimation (Kingma & Ba, 2014) - combines momentum with per-parameter adaptive step sizes. Fast convergence on sparse-gradient problems (NLP, recommenders); sometimes worse final-epoch generalisation than SGD on image tasks., and RMSpropRoot Mean Square propagation - Adam without the momentum term. Maintains a running average of squared gradients to normalise step sizes per parameter. Used heavily in RNN training where gradient magnitudes vary wildly per step. fight their way across a contoured loss surface in real time. Recording at the top.
The webinar in numbers
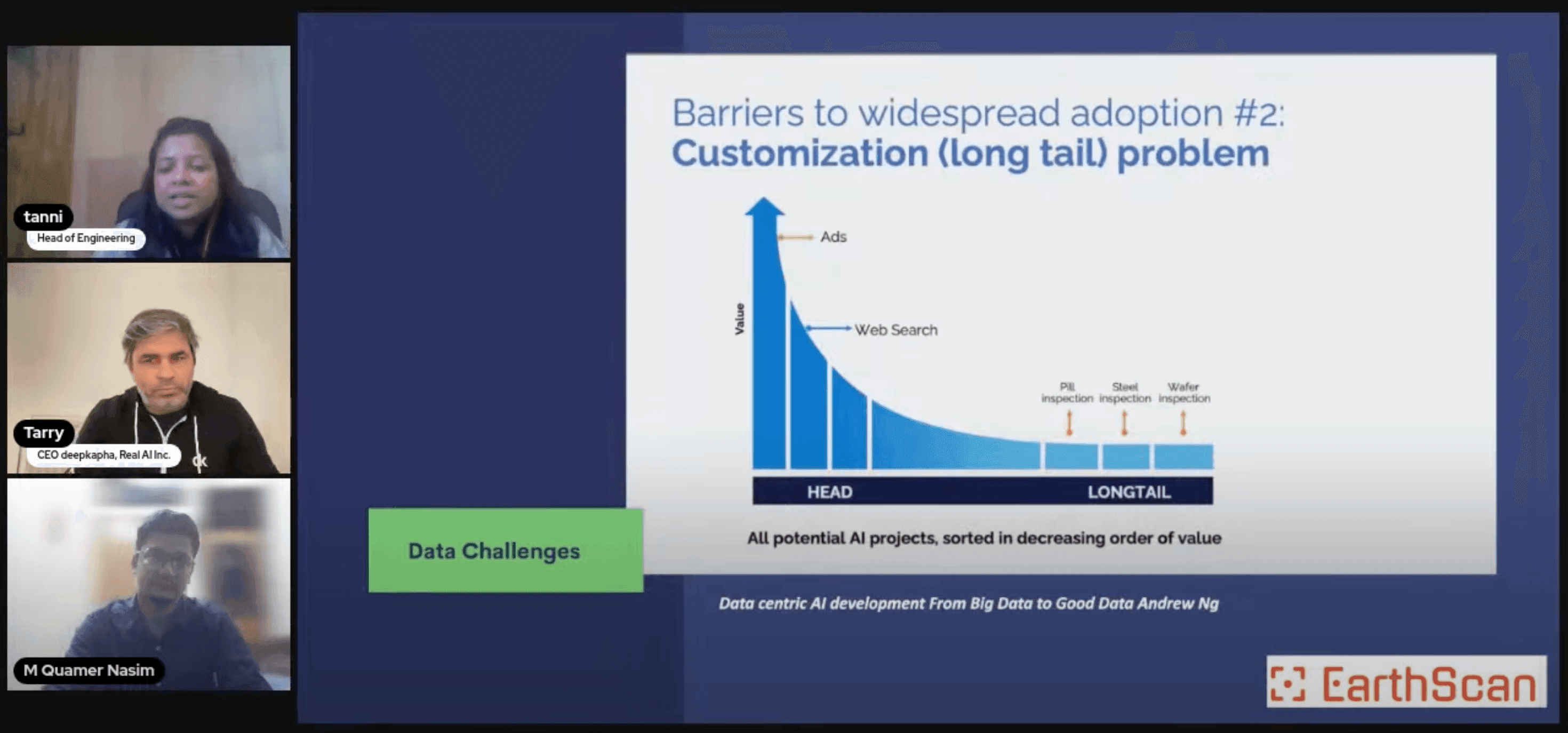
Optimiser families covered (SGD, SGD+momentum, Adam, AdamW, RMSprop)
LR schedule shapes (step / exponential / cosine / cyclic / one-cycle)
Hyperparameter that beats most architecture choices: the learning rate
Bergstra & Bengio's headline - random search beats grid at the same compute budget
Pick a schedule · See its shape
5 LR schedules, 5 personalities
Click any tile to see what the schedule does to your learning rate, when it earns its keep, and which optimiser family it pairs with cleanly.
Optimisers - picking the right gradient-descent flavour
Optimisers determine how parameters get updated each backprop step by minimising the loss function. The popular choices and where each one earns its keep:
- Stochastic Gradient Descent (SGD) - the workhorse. Slow and noisy, but its noise is a feature: SGD with momentum routinely matches Adam on image classification at convergence and generalises better. Pick it when you have time + a large dataset.
- Adam - adaptive per-parameter step sizes. Fast convergence, especially on sparse gradients (NLP, recommender systems). Pays for it with worse final-epoch generalisation than SGD on some computer-vision tasks.
- RMSprop - the "Adam without the momentum" baseline. Still useful for RNNs where the gradient distribution is wildly per-step.
- AdamWAdam with decoupled weight decay (Loshchilov & Hutter, 2017). Closes most of the generalisation gap that vanilla Adam leaves on the table - the modern transformer default. - Adam with decoupled weight decay. Closes most of the generalisation gap that vanilla Adam leaves on the table.
The right pick is task-dependent - but the meta-rule is simple: don't use Adam if SGD with momentum will converge in your training-time budget.
Learning-rate schedulers - making the optimiser navigate well
The learning rate is the step size. It's the single most influential hyperparameter in deep learning, and a fixed learning rate is almost never optimal - too high early on causes divergence, too low late on causes plateaus.
The schedules we covered:
- Step decay - drop the LR by a factor every N epochs. Simple, brittle. Works when you know the right N.
- Exponential decay - continuous decay. Smoother than step.
- Cosine annealingA learning-rate schedule that decays the LR following a half-cosine curve from initial value to zero across the training horizon. Smoother than step decay, less aggressive than exponential - the empirical winner for image and language pretraining since 2018. - decay along a half-cosine. Empirically strong on image and language pretraining.
- Cyclic learning ratesA learning-rate schedule (Smith, 2017) that oscillates between a base and max value following a triangle wave. The high LRs help the optimiser escape sharp local minima and find flatter ones (better generalisation). (Smith, 2017)Smith · 2017Cyclical Learning Rates for Training Neural NetworksWACV - oscillate between a low and a high LR. Lets the optimiser escape sharp minima.
- One-cycle policySmith's super-convergence schedule - a single triangular cycle that warms up to a max LR then anneals to nearly zero. Reaches strong minima in fewer epochs than constant-LR training. The modern fine-tuning default. - Smith's follow-up, a single triangular cycle. The most reliable "default schedule" for fine-tuning today.
Pick the schedule after you've picked the optimiser, and tune them together - a great LR for SGD is a terrible LR for Adam.
Watching the trade-offs in action
The webinar walked through real examples across computer vision, NLP, and recommendation systems. Two patterns held up in every example:
- Optimiser choice matters most early in training. The first few epochs are when you're far from any minimum and the geometry differences between SGD, Adam, and RMSprop are largest.
- LR-schedule choice matters most late in training. Once you're near a minimum, the schedule decides whether you settle into a flat basin (good generalisation) or a sharp one (bad generalisation, even if the train loss is lower).
If you have to pick one to obsess over, pick the schedule.
Optimiser choice matters most early; LR-schedule choice matters most late. The first epochs decide whether you converge at all; the final ones decide whether you settle into a flat basin (good) or a sharp one (bad).
Hyperparameter tuning - not optional
Every optimiser and every schedule introduces hyperparameters: initial LR, momentum, β₁/β₂ for Adam, the cycle period for cyclic LR, etc. The webinar covered three approaches to finding good values:
- Grid search - brute-force, only viable when you have ≤ 3 hyperparameters.
- Random search - strictly better than grid search at the same compute budget (Bergstra & Bengio, 2012)Bergstra & Bengio · 2012Random Search for Hyper-Parameter OptimizationJMLR 13. The default "no-thinking" baseline.
- Bayesian optimisationHyperparameter-search technique that builds a probabilistic model of the validation-loss surface as it tries hyperparameter combinations. Pays for itself when single training runs are expensive (>24 GPU-hours). - Gaussian-process or TPE-based search that builds a model of the validation-loss surface as it goes. Pays for itself when each training run is expensive.
For most production projects, random search over a reasonable hypercube is the pragmatic choice. Reach for Bayesian optimisation when single training runs cost > 24 GPU-hours.
Takeaways
Three things to remember when your model isn't converging:
- Try SGD with momentum before Adam. It might just need patience.
- One-cycle schedule is a strong default. Especially for fine-tuning.
- Tune the optimiser and the schedule together, not separately. They interact.
Further reading
- A comprehensive guide on deep learning optimizers - Analytics Vidhya
- The best learning rate schedules - Towards Data Science
- A gentle introduction to hyperparameter tuning - Kaggle notebook
Key takeaways
- Try SGD with momentum before Adam. It might just need patience - and it generalises better at convergence on most computer-vision tasks.
- One-cycle policy is a strong default for fine-tuning: warm up, then anneal - Smith's super-convergence recipe gets to a strong minimum in fewer epochs.
- Tune the optimiser AND the schedule together, not separately. They interact - a great LR for SGD is a terrible LR for Adam.
- Random search beats grid search at the same compute budget (Bergstra & Bengio, 2012). Reach for Bayesian optimisation when single training runs cost > 24 GPU-hours.
Glossary
- Adam
- Adaptive Moment Estimation (Kingma & Ba, 2014) - combines momentum with per-parameter adaptive step sizes. Fast convergence on sparse-gradient problems (NLP, recommenders); sometimes worse final-epoch generalisation than SGD on image tasks.
- AdamW
- Adam with decoupled weight decay (Loshchilov & Hutter, 2017). Closes most of the generalisation gap that vanilla Adam leaves on the table - the modern transformer default.
- Bayesian optimisation
- Hyperparameter-search technique that builds a probabilistic model of the validation-loss surface as it tries hyperparameter combinations. Pays for itself when single training runs are expensive (>24 GPU-hours).
- Cosine annealing
- A learning-rate schedule that decays the LR following a half-cosine curve from initial value to zero across the training horizon. Smoother than step decay, less aggressive than exponential - the empirical winner for image and language pretraining since 2018.
- Cyclic LR
- A learning-rate schedule (Smith, 2017) that oscillates between a base and max value following a triangle wave. The high LRs help the optimiser escape sharp local minima and find flatter ones (better generalisation).
- One-cycle policy
- Smith's super-convergence schedule - a single triangular cycle that warms up to a max LR then anneals to nearly zero. Reaches strong minima in fewer epochs than constant-LR training. The modern fine-tuning default.
- Random search
- Hyperparameter-search baseline that samples random points in the hyperparameter hypercube. Bergstra & Bengio (2012) showed it strictly dominates grid search at the same compute budget - because most hyperparameters don't matter equally and grid search wastes samples on the unimportant axes.
- RMSprop
- Root Mean Square propagation - Adam without the momentum term. Maintains a running average of squared gradients to normalise step sizes per parameter. Used heavily in RNN training where gradient magnitudes vary wildly per step.
- SGD
- Stochastic Gradient Descent - updates model parameters in the direction of the negative gradient computed on a mini-batch. The classical, noise-friendly optimiser; with momentum, still competitive on image classification at convergence.