“Deep learning is genuinely transforming subsurface workflows. The transformation is uneven - and the difference between a successful deployment and a stalled one is whether the team understood, before kick-off, which architecture earns its keep on which application.
”
A practitioner-oriented walkthrough of deep learning in geoscience and subsurface exploration: where it earns its keep, where the academic literature over-promises, and what a working subsurface AI stack looks like in 2020+ terms.
The architecture × application landscape
The literature on deep learning in subsurface is large and growing. What it's short on is the fitness-by-application matrix: which architecture earns its keep where, and where it's a research-stage demo that hasn't made it to production.
Click any cell to read the specific fit, the operational caveat, and the open sub-problem.
| Architecture ↓ / Application → | Seismic interpretation | Reservoir characterisation | Fault detection | Log analysis | Resolution / denoising |
|---|---|---|---|---|---|
| CNN | |||||
| U-Net | |||||
| GAN | |||||
| RNN / LSTM | |||||
| Transformer | |||||
| Self-supervised pretraining |
What "subsurface exploration" actually means
Geoscience covers the Earth's composition, structure, and processes. Subsurface exploration is the branch focused on what's beneath the surface - natural resources, geological formations, energy reservoirs - and historically it depended on highly experienced humans interpreting seismic surveys, well logs, and core samples by hand.
That manual-interpretation premise is what deep learning is now eroding. The question isn't whether AI can do parts of this work - it provably can - but which parts, with what reliability, and at what cost to ship in production.
For background reading: Edinburgh Geosciences research maintains a strong open page on the discipline.
Deep learning in seismic imaging
Seismic imaging produces 2D and 3D pictures of the subsurface from acoustic-wave reflection data. The processing chain - migration, denoising, resolution enhancement - is computationally heavy and traditionally requires expert tuning.
Where deep learning helps:
- Convolutional neural networks (CNNs) for automated interpretation - picking horizons, salt bodies, channel features. Trained on annotated 3D volumes, CNNs match expert interpreters on the routine cases and free up the expert for the hard ones.
- Generative adversarial networks (GANs) for resolution enhancement and denoising - the discriminator pushes the generator toward outputs that statistically match high-quality field data. Works well when the noise model is poorly understood.
- Self-supervised pretraining on un-annotated volumes - labels are scarce in this domain; SSL turns "we have lots of unlabelled data and a few labelled volumes" into a useful learning signal.
The catch: out-of-distribution generalisationTest data that statistically differs from training data - a model trained on Gulf of Mexico salt seeing pre-salt Brazil for the first time. The single most under-reported failure mode in published academic results.. A model trained on Gulf of Mexico salt won't recognise pre-salt Brazil structures without re-training. Vendors who claim a single universal model are selling.
See SPE's overview on AI in oil & gas for the operator-side perspective on deployment.
Reservoir characterisation and prediction
Reservoir characterisation predicts subsurface properties - porosity, permeability, fluid saturation, rock-type - from log and seismic data. Deep learning's contribution here is well-explored:
- Recurrent neural networks (RNNs) and long short-term memory (LSTM) networks model depth-sequenced log data as time-series-like inputs. They capture the dependency of a layer's properties on what's directly above and below.
- Hybrid CNN-LSTM models combine spatial features (from 2D or 3D log/seismic windows) with sequential dependencies. Strong on multi-well correlation tasks.
- Bayesian deep learningVariational dropout, MC-Dropout, ensembles - techniques that turn a single point-estimate model into a distribution over predictions. Procurement-side industries (insurance, regulation) increasingly demand it. layers (variational dropout, MC-Dropout) on top of the above architectures give you uncertainty estimates - which the procurement-side industries (insurance, regulation) increasingly demand.
The honest framing: deep learning improves point estimates by 5-15% over classical empirical models on most reservoir-characterisation benchmarks. The real win is uncertainty quantification - knowing when the model doesn't know.
Fault detection and analysis
Identifying faults and fractures is critical for both geohazard assessment (drill-bit kicks, wellbore stability) and hydrocarbon exploration (faults can be both seals and conduits). Manual interpretation on a 3D seismic cube is laborious and inconsistent across interpreters.
Deep learning approaches that work:
- Deep CNNs trained on patches of seismic with binary fault/no-fault labels. Works for the common, well-imaged faults.
- Unsupervised / self-supervised learning - Watton et al. (2014) and later work shows that contrastive pretraining on un-annotated volumes reduces the labelled-data requirement by 5-10×.
- U-Net-style segmentation for full-volume fault probability maps. Output is interpretable as "every voxel has a probability of belonging to a fault" - useful for downstream uncertainty propagation.
Open-source code for fault-detection deep learning lives at github.com/topics/fault-detection.
The unsolved problem in this space is continuity - segmenting a single connected fault surface across an entire 3D cube, rather than detecting fault voxels independently. Most production tools today do post-hoc clustering on per-voxel probabilities; the resulting fault networks are noisy and need expert clean-up.
Where the literature over-promises
Three places to read journal papers carefully:
- Train-test split contamination. Many published results train and test on adjacent slices of the same 3D volume. Real performance on a new field is far worse than the headline accuracy.
- Cherry-picked datasets. Public benchmarks (F3, Penobscot, Kerry) are limited and well-imaged. Real archives include 50-year-old paper logs and 1990s-vintage 2D seismic with terrible signal-to-noise ratios.
- Inference cost. Training a model is a one-time bill. Running it across decades of historic archive volumes is the recurring cost - and it's almost never reported in academic papers.
A working production AI stack for subsurface budgets for all three of these realities upfront.
Case studies and where to dig deeper
Real-world success stories from operator-side deployments are increasingly available - both SPE and Springer have edited volumes covering specific projects. The pattern across them:
- The wins are always domain-specific (one operator, one basin, one log vintage).
- The teams that succeeded paired a domain-expert geoscientist with the ML engineers from day one.
- The teams that failed treated AI as a procurement decision rather than a capability build.
Glossary
- Bayesian deep learning
- Variational dropout, MC-Dropout, ensembles - techniques that turn a single point-estimate model into a distribution over predictions. Procurement-side industries (insurance, regulation) increasingly demand it.
- Out-of-distribution
- Test data that statistically differs from training data - a model trained on Gulf of Mexico salt seeing pre-salt Brazil for the first time. The single most under-reported failure mode in published academic results.
- Self-supervised learning
- Training signal from the data itself - predict the next pixel, the missing slice, the augmented contrast - without human labels. Critical when labels are scarce, which is always the case in geophysics.
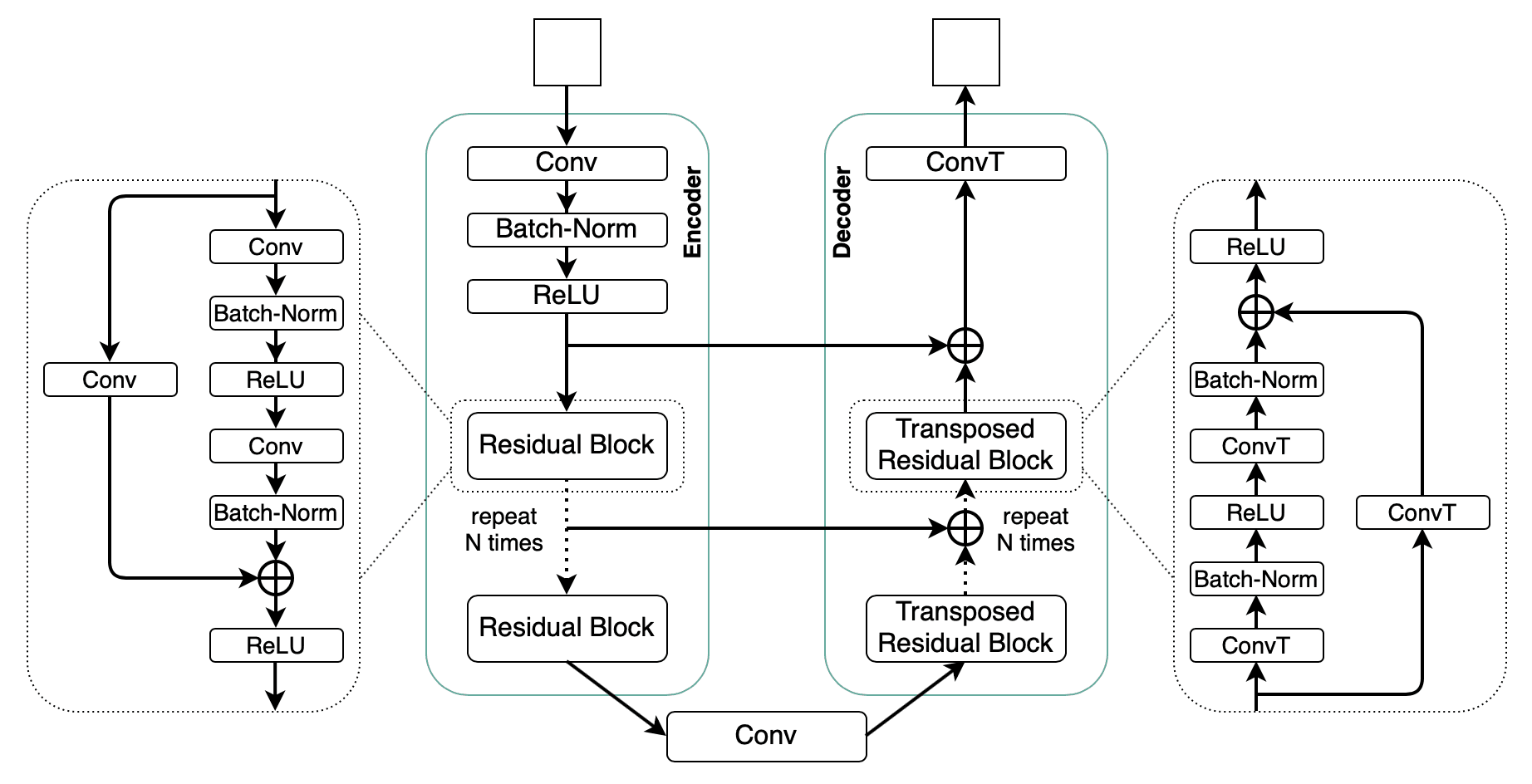
- U-Net
- Encoder-decoder architecture with skip connections that became the default backbone for pixel-wise segmentation. The skip connections are the trick - let the decoder recover spatial detail lost in the bottleneck.
Closing thought
Deep learning is genuinely transforming geoscience and subsurface workflows. The transformation is uneven: parts of the workflow (seismic interpretation, log digitisation) are 10× easier; other parts (fault continuity, reservoir simulation) are still mostly classical methods with an ML cherry on top.
The operators winning this transition are the ones investing in internal capability - not just model libraries, but the data pipelines, MLOps practice, and cross-disciplinary teams that turn a paper into production.